You Only Debug Once? Think again
How good are the top frontier LLMs at finding bugs? I ran a small experiment to find out — and yes, the results surprised me!

A few days ago I was looking at this very complex codebase, freshly vibe-coded, that I strongly suspected would be full of bugs.
So I did what I normally do and I asked Claude Code (Opus 4.6) to have a first pass at bug-finding. It gave me its findings but while I was reading, I thought… wait, would Codex find the same bugs? And Gemini? What about our new star Kimi 2.5?
And what if you run each of them again? Will they find the same stuff every time?
Alrighy then, *stretches fingers* let’s run this
Our contenders:
gpt-5.3-codex-medium (via Codex CLI)
claude-4.6-opus (Claude Code)
gemini-3-pro-preview-high (OpenCode)
kimi-k2.5 (OpenCode)
Prompt:
observe [file] and related files that run missions:
- what is your take on the implementation? is anything obviously wrong? can you spot any bugs or lacks?
- first list your findings, then summarize them in a table with Severity / Area / Issue / Evidence (files) / Impact
Experiments
I ran each of the 4 agents 3 times — each time with entirely clean context, same prompt and repo state unchanged.
Collected all the output in one coalesced file, with headers noting the run # and the agent
Normalized the definition and severity of each bug found by feeding all the results to Gemini, Codex and Kimi, then cross-checked the bug definitions to ensure consistency. (Claude failed at this task as it kept trying to debug the repo again instead of sticking to the documents! - Kept telling me those bugs were stale because we’d fixed them already since)
Using the normalized bug definitions, and the full output, I then got Gemini to create the table you can find in the summary
The bugs we found
The various agents mostly agreed on how to aggregate the individual bugs, and the top 5-6 were pretty consistent, but disagreed on the severity of each.
I concluded Critical / High / Medium were assigned pretty much by throwing darts in a pub so I ended up manually touching up the consolidated table and made everything High or Critical as you can see below.
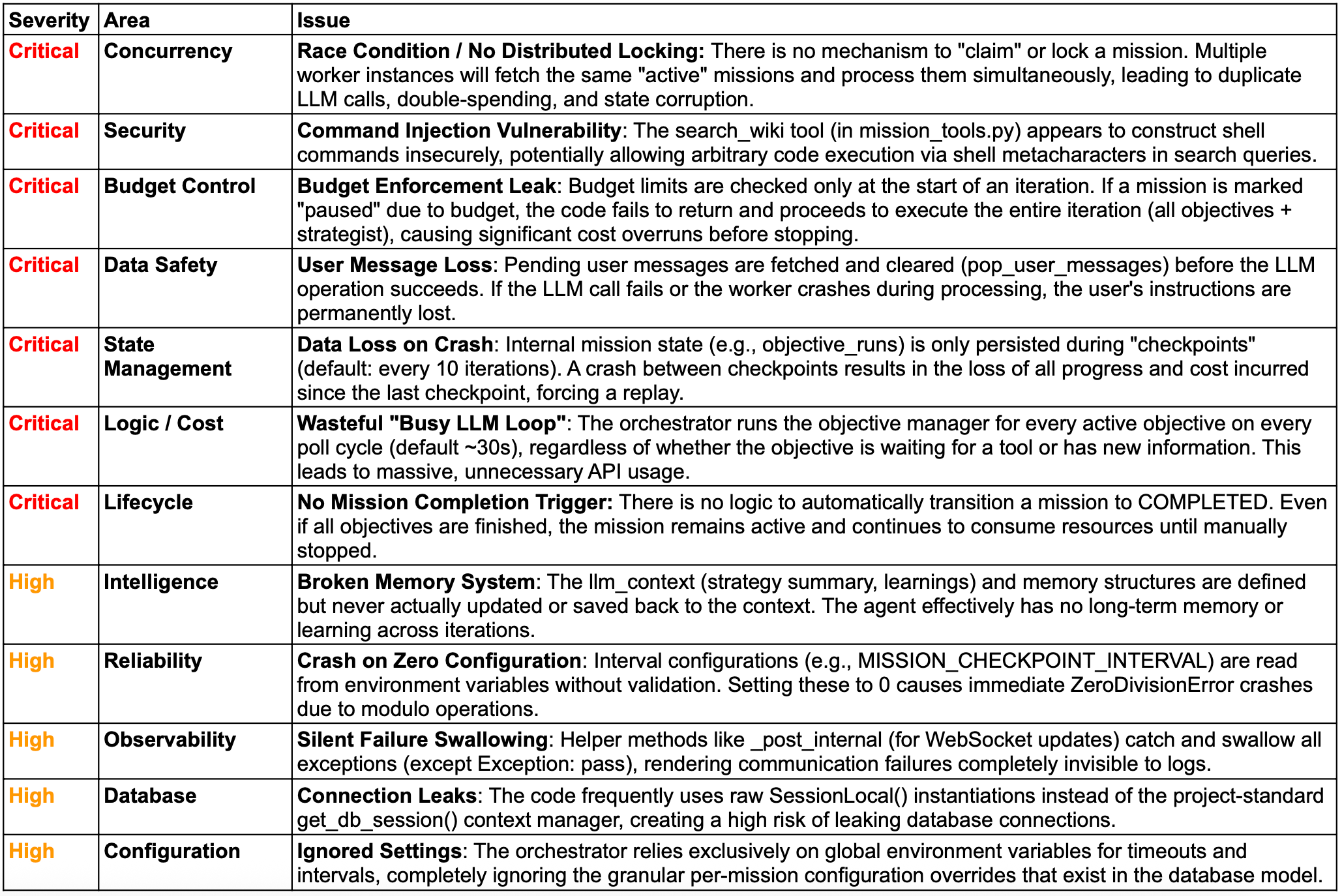
Ok so that’s a lot of bugs — are they real?
Yes! I can confirm each of them was real, and I can confirm I found more afterwards.
Cross-run model consistency
So how consistent were the models at finding these? They are, after all, stochastic next-token predictors, right?
Well I guess here goes a point to the “stochastic parrots” crowd.
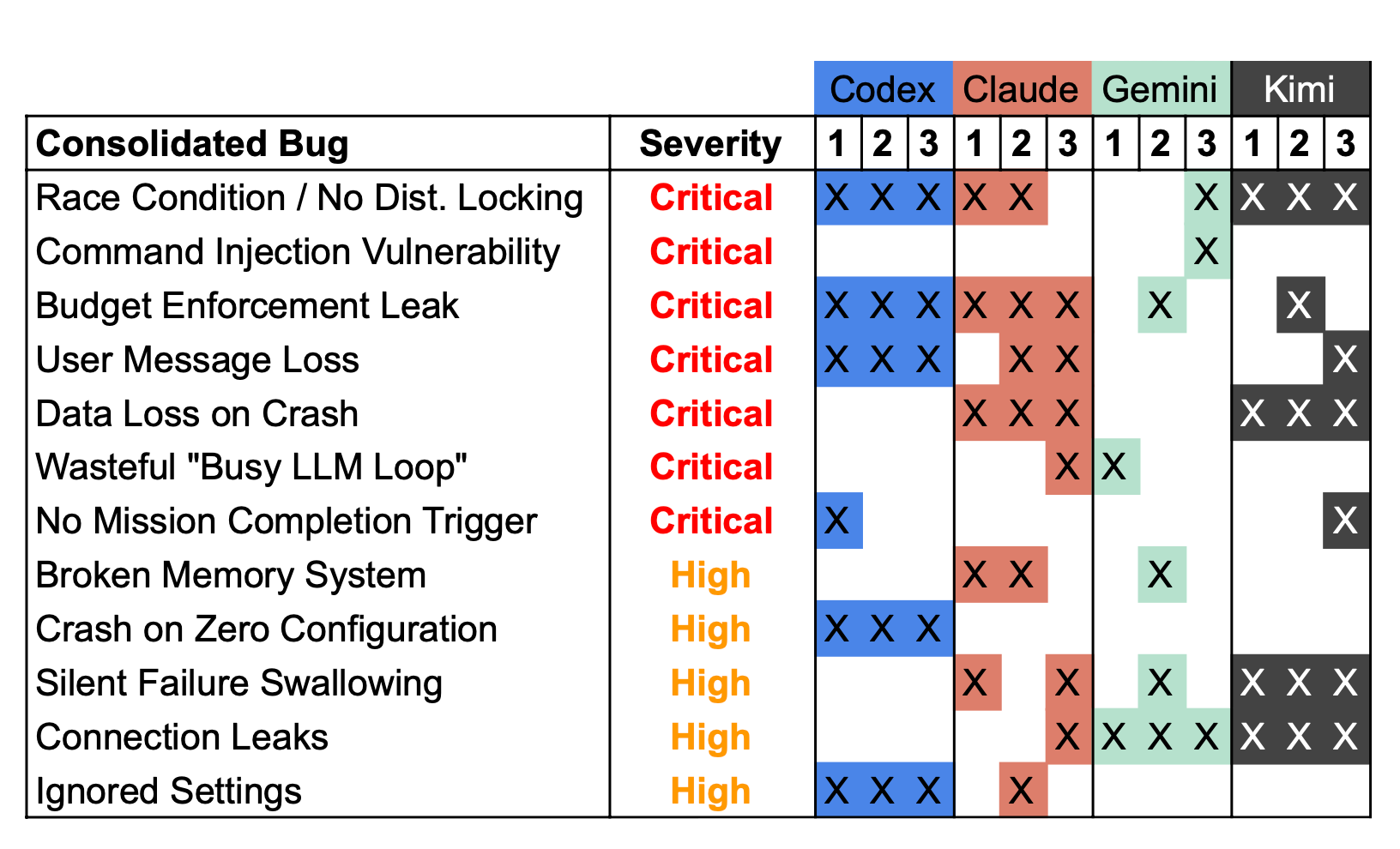
Results summary
Here is a summary of the findings written by Codex:
Claude: Best overall breadth and strongest at deep reliability/state-machine style bugs. Weakness: less consistent across 3 runs and tends to include more speculative findings.
Kimi: Strong reliability auditor (state persistence, session/concurrency, silent failure patterns) with good critical recall. Weakness: narrower coverage and some repetitive pattern-based calls.
Gemini: Most “spiky” profile. Biggest strength is unique security intuition (command injection was Gemini-only in the matrix). Weakness: highest variability and less stable signal across reruns.
Codex: Most repeatable and disciplined on core operational/config risks (especially zero-config crash + ignored settings). Weakness: narrower discovery range, misses several deeper lifecycle/reliability issues.
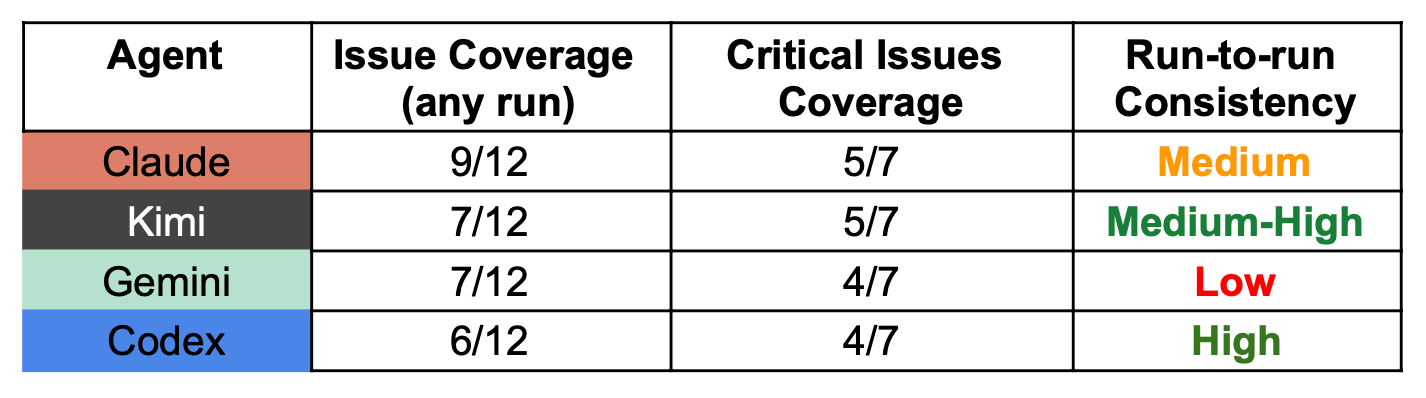
Note: When Opus 4.6 had to score how well the different agents did, it hallucinated for itself extra points that weren’t in the data (!). Gemini 3 Pro put itself first on the table and the results and obsessed about the security vulnerability it found (on 1/3 runs!), making it seem as the most important finding. Codex seemed less biased towards giving itself more points.
Conclusion
So, which AI wins? Honestly… none of them.
As you can see, the matrix is pretty peppered and in some instances with complementary findings:
Gemini was the only one to (correctly!) identify the command injection (1/3 times), but also the only one that failed to identify the critical “user message loss”, and also terrible at consistency across runs
Codex was the only one to spot the potential “division by zero” bug (3/3 times) but also missed several critical ones
But you, my senior software engineer friend, might have been wondering all along: who the hell debugs code by just looking at it?
Well, you are of course correct! You would start by writing some unit / integration / system tests and build on those, right?
But some of these bugs listed might only be found by running full stack system tests! And in order to even know which tests to write and where things might break, you need to have some measure of understanding of the moving pieces, their interactions and what the state looks like.
So, is this a useful test of the LLM’s understanding of our code? Or are these big sacks of weights simply spotting patterns?
What can we take away from this?
I still find it extremely useful to throw the LLM at predicting bugs before even running your code — it’s like doing a first pass at catching stuff before it happens, saving you time after. Like “galaxy brain linting”.
But now I have proof of its limits: like everything with LLMs, it’s intrinsically stochastic and you can’t fully trust it without deterministic tests
Kimi 2.5 came out as a surprisingly powerful model in these tests, doing on par with all the other frontier models and indeed, I’d say, better than Gemini 3 Pro.
Have you found Gemini and Claude bumping their own scores over repeated runs?